How Alpha Go Work (วิธีการทำงาน)
บทความเขียนเรียบเรียงโดยคุณ panote_saechiew
อ่านเพิ่มเติมที่ http://pantip.com/topic/34896422
https://www.facebook.com/notes/panote-saechiew/how-alpha-go-work/1340692295948067
gunhotnews ขอขอบคุณครับ
มาดูกันดีกว่าครับว่า Alpha Go ทำงานยังไงข้อมูลที่ใช้ในการเขียนแกะมาจาก
Mastering the game of Go with deep neural networks and tree search
ซึ่งเป็นเปเปอร์ของทีม Deep Mind ครับ
ผมคงไม่ได้ลงลึกในรายละเอียดมากนัก(เพราะยากมาก ผมก็เข้าใจไม่หมด)
แต่จะอธิบายภาพใหญ่ๆของการทำงานของมัน
ก็ตามชื่อบทความ นั่นคือตัว Alpha Go
นั้นผสมผสานเทคนิคสองอย่างเข้าด้วยกันคือ Tree Search และ Neural
Networks(NN) หรือเครือข่ายประสาทเทียม ผมคงไม่ลงรายละเอียดว่า NN
ทำงานยังไง เอาสรุปง่ายๆว่า มันเป็นกล่องที่จะให้คำตอบ โดยคำตอบที่ได้
มาจากการเรียนรู้ละกันครับ
กูเกิลแบ่งขั้นตอนการสร้าง NN เป็น 3 ขั้น นั่นคือ
1. สอน : NN ได้รับการป้อนบันทึกหมากจำนวน 30 ล้านตาเดิน แล้วให้พยายาม
“เดา” หมากเม็ดถัดไปที่จะเดินลงมา NN ในขั้นนี้มี 2 ตัว คือ SL Policy และ
Rollout Policy ซึ่งเหมือนกันทุกอย่างต่างกันตรงเวลาคิด(SL Policy
ใช้เวลาหาคำตอบ 3 millisecond ส่วน Rollout ใช้ 2 microsecond
แต่ความแม่นก็ต่างกันครึ่งต่อครึ่ง)
2. ซ้อม : เอา SL Policy จากขั้นตอนแรก
มาแข่งกับตัวมันเอง(ในเวอร์ชั่นก่อนๆ)จนได้ข้อมูลมาอีก 30
ล้านตาเดินแล้วให้คะแนนถ้าตาเดินนั้นทำให้ชนะ
ผลที่ได้จากขั้นตอนนี้เรียกว่า RL Policy กูเกิลบอกว่า RL Policy ชนะ SL
Policy ได้มากกว่า 80% และลำพัง RL Policy
ก็เพียงพอจะชนะโปรแกรมโกะอื่นๆในโลกมากกว่า 85%
3. สังเคราะห์ : เพื่อให้การตัดสินใจกว้างขึ้น กูเกิลตัดสินใจสร้าง NN
ขึ้นอีกหนึ่งตัวที่ให้คำตอบเป็นความน่าจะเป็นที่จะชนะของการลงหมากในแต่ละ
ตำแหน่ง(Probability to win) NN ตัวนี้ได้จากตำแหน่งหมากเวลาใดๆ
เทียบกับผลลัพธ์สุดท้ายว่าเกมนั้นชนะหรือแพ้ ข้อมูลที่ใช้ได้จากการใช้ RL
Policy แข่งกับตัวมันเอง อีก 30 ล้านตาเดิน เรียกว่า Value Policy
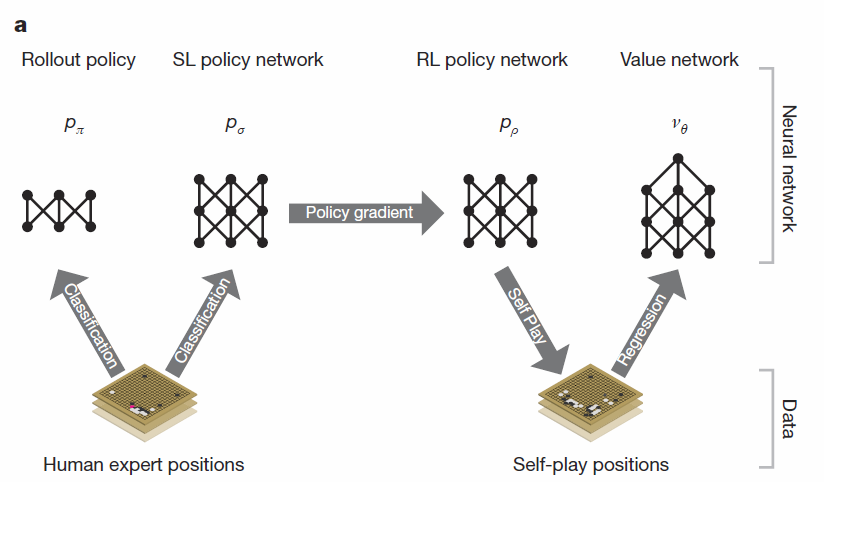
ภาพที่ 1 แสดงที่มาของ policy ทั้ง 4 ตัว
ถึงตรงนี้ รากฐานการประเมินของ Alpha Go พร้อมแล้ว
ขั้นตอนถัดไปคือการเอามาใช้ ขอพักคอมพิวเตอร์ไว้แป๊ปนึง
กลับมาลองนึกถึงเราเองว่าเวลาเราเล่นหมากรุก หรือโกะ นี่เราเล่นยังไง
ผมว่าโดยรวมหลายๆคนจะเริ่มแบบนี้ครับ
1. กวาดตากว้างๆดูกระดาน ตัดตาเดินที่ไม่เมกเซนต์ออกไปให้หมดก่อน
2. ทดลองเดินดู(ในใจ) แล้วเดาว่าฝ่ายตรงข้ามจะเดินตอบโต้ยังไง
3. ย้ายไปลองเดินตาอื่น แล้วประเมินการตอบโต้
4. เลือกตาเดินที่ดีที่สุด
สิ่งที่กูเกิลทำก็ตามนั้นละครับ เทคนิคที่ใช้ในการนี้เรียกว่า Monte carlo Tree Search
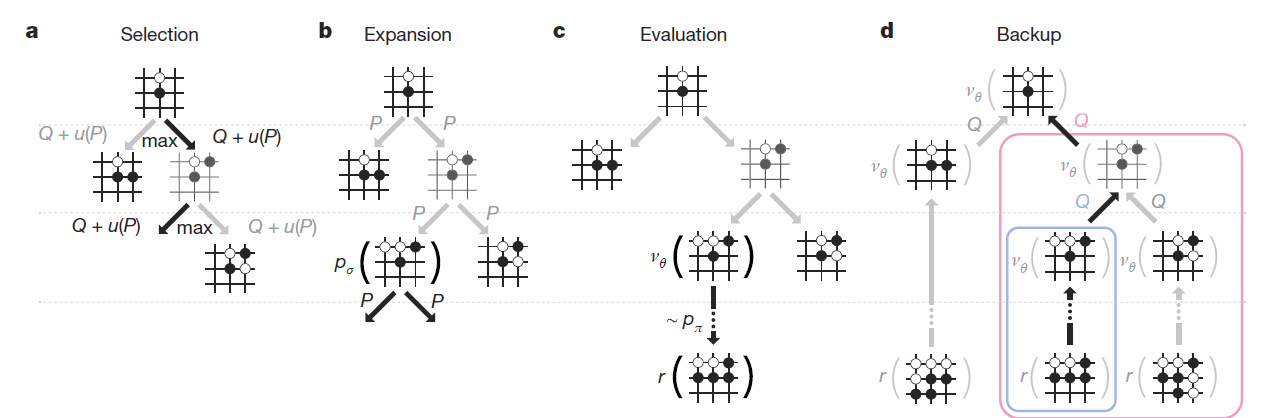
ภาพที่ 2 Monti Carlo Tree Search
1. จากภาพโปรแกรมจะเริ่มจากการกวาดตากว้างๆ หนึ่งรอบ
ประเมินตาเดินทั้งหมดที่เป็นไปได้ ขั้นตอนนี้ใช้ SL Policy
(ถ้าเป็นโปรจะเดินยังไง)ให้คะแนนแต่ละทางเลือก
2. เอาทางเลือกที่คะแนนดีๆ มาลองคิดต่อ โดยลองเดินตาถัดไปหลายๆแบบ โดยใช้ทั้ง SL Policy(โปรเดิน) RL Policy(เดินเอง)
3. ให้คะแนนแต่ละทางเลือกโดยใช้ Value Policy(เดินแบบนี้มีโอกาสชนะเท่าไหร่)ควบกับ Rollout Policy (ลองเดินต่อให้จบแบบหยาบๆ)
4. ทดลองเดินต่อจากข้อสอง(คือเดาหมากถัดไปอีกชั้น)
กระบวนการนี้จะวนไปเรื่อยๆ จนกว่าจะได้ผลลัพธ์ที่น่าพอใจ แล้วก็จะเลือกทางเดินที่ดีที่สุดไปใช้
มาดูตัวอย่างกันครับ
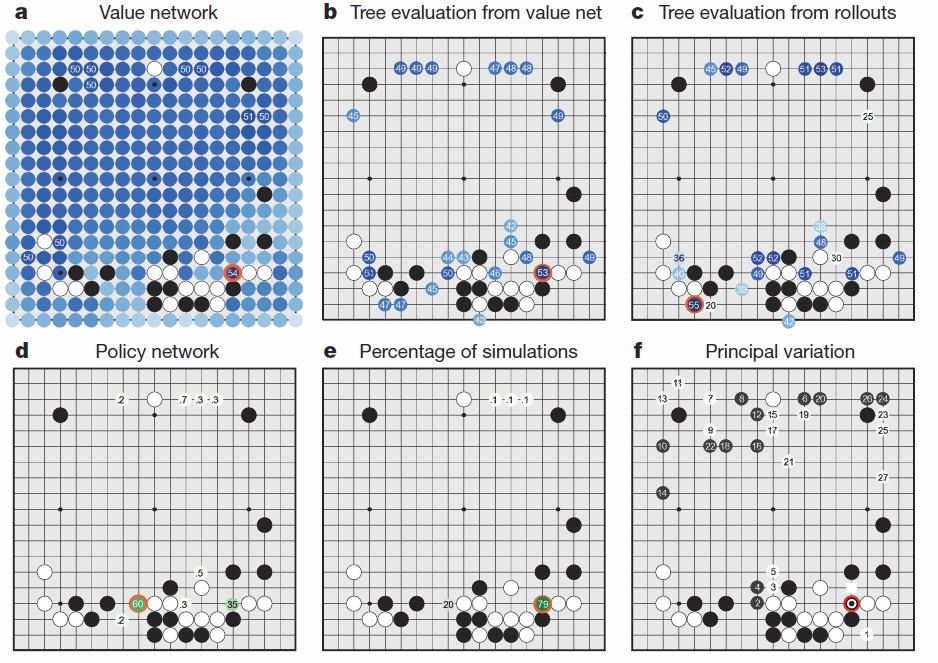
a. โปรแกรมทำการประเมินโอกาสชนะของตาเดินทั้งหมดโดยใช้ value policy ที่เป็นไปได้ สีเข้มคือน่าเดิน สีอ่อนคือไม่น่าเดิน ที่มีสีแดงวงไว้ คือตาเดินที่มีโอกาสสูงสุด
b.-d. คะแนนคำนวณแต่ละตำแหน่งจาก policy ต่างๆกัน
e. หมากที่โดนวงไว้คือ ตาเดินที่มีความน่าจะเป็นสูงสุดที่จะชนะ
f. คือรูปแบบการเดินที่พยากรณ์ไว้ทั้งหมดก่อนเดินตานี้ ซึ่ง ฟานฮุ่ย ลงหมากที่ตำแหน่ง 1 ตามที่ Alpha Go พยากรณ์ไว้
จบแล้วครับ สำหรับโครงสร้างคร่าวๆของ Alpha Go ใครจะต่อขยายภาคพิศดารก็เชิญตามสะดวก
บทความเขียนเรียบเรียงโดยคุณ panote_saechiew
อ่านเพิ่มเติมที่ http://pantip.com/topic/34896422
https://www.facebook.com/notes/panote-saechiew/how-alpha-go-work/1340692295948067
gunhotnews ขอขอบคุณครับ
ผู้โพส: gunhotnews ![]()
วันที่: 13 มี.ค. |+2016| 22:15
จำนวนคนเข้าชมทั้งหมด:6828
หมวด: วิทยาศาสตร์
| 25 ก.พ. |+2016| 23:16 |
| 13 มิ.ย. |+2015| 21:46 |
| 29 เม.ย. |+2015| 00:40 |
| 27 มี.ค. |+2015| 21:22 |
| 21 มี.ค. |+2017| 08:50 |
จำนวนคอมเม้น: 7
1
I wanted to post you one tiny word in order to give many thanks the moment again for the lovely ideas you have shared here. It has been shockingly open-handed of people like you to supply easily what exactly a number of us could possibly have distributed as an e book to generate some money for themselves, and in particular considering that you might well have done it if you ever desired. The tactics also worked to provide a great way to understand that other people have the identical zeal the same as my own to know the truth very much more when considering this matter. I think there are millions of more pleasurable occasions in the future for many who look over your blog post.
jordan retro http://www.jordan-retro.us.com
ผู้โพส: jordan retro วันที่:13 เม.ย. |+2023| 14:57


![]()
2
I wish to convey my passion for your kindness for men who need help with that area. Your real dedication to passing the message all-around had become remarkably important and has all the time made folks just like me to get to their endeavors. This warm and friendly help and advice means a great deal a person like me and a whole lot more to my fellow workers. Warm regards; from all of us.
nike sb http://www.sbdunk.us
ผู้โพส: nike sb วันที่:29 มี.ค. |+2023| 13:29
![]()
3
I must point out my admiration for your kindness supporting people that really want help with your content. Your personal commitment to passing the solution all around had been definitely invaluable and has without exception made somebody just like me to achieve their goals. The useful information can mean a whole lot a person like me and still more to my colleagues. Many thanks; from everyone of us.
palm angels hoodie http://www.palmangels.us.com
ผู้โพส: palm angels hoodie วันที่:27 ต.ค. |+2022| 12:55
![]()
4
pandora charms germany christmas ray ban rb3025 flash drives prada tessuto gaufre bn1788 mackage messenger room for one more leather ugg boots with laces real ferragamo belt box
keiservices http://www.keiservices.com/
ผู้โพส: keiservices วันที่:13 พ.ย. |+2018| 23:27
![]()
5
เพิ่มเติมจากคุณ AKB-SKE เว็บไชต์พันทิป
 Aja (Shih-Chieh) Huang
จบ Ph.D จาก มหาวิทยาลัยแห่งชาติไต้หวัน ในหัวข้อ New Heuristics for Monte Carlo Tree Search Applied to the Game of Go
เป็นนักเล่นโกะ ระดับ 6 ดั้ง
ทำงาน Post doc ที่ University of Alberta ก่อนจะเข้าร่วมงานที่ DeepMind
ทำหน้าที่เป็นคนเดินหมากให้ AlphaGo ด้วย
Aja (Shih-Chieh) Huang
จบ Ph.D จาก มหาวิทยาลัยแห่งชาติไต้หวัน ในหัวข้อ New Heuristics for Monte Carlo Tree Search Applied to the Game of Go
เป็นนักเล่นโกะ ระดับ 6 ดั้ง
ทำงาน Post doc ที่ University of Alberta ก่อนจะเข้าร่วมงานที่ DeepMind
ทำหน้าที่เป็นคนเดินหมากให้ AlphaGo ด้วย
ผู้โพส: gunhotnews ![]() วันที่:13 มี.ค. |+2016| 22:26
วันที่:13 มี.ค. |+2016| 22:26
![]()
6
เพิ่มเติมจากคุณ AKB-SKE เว็บไชต์พันทิป
 Demis Hassabis
หนึ่งในผู้ก่อตั้ง DeepMind
จบ computer science จาก Cambridge รุ่นเดียวกับ David Silver
และเป็นคนสอน David Silver เล่นโกะด้วย
เป็นอัจฉริยะ ด้านหมากรุก โดยได้ คะแนนระดับ Chess Master ตอนอายุ 14 ปี อายุน้อยเป็นอันดับ 2 ของโลก ณ เวลานั้น
จบปริญญาเอกที่ University College London
ก่อตั้ง DeepMind ในปี 2010 ปี 2014 Google มาเทคโอเวอร์ ด้วยเงิน 400 ล้านปอนด์
ปัจจุบัน มีตำแหน่งเป็น รองหัวหน้า ด้านวิศวกรรม AI ของ Google
Demis Hassabis
หนึ่งในผู้ก่อตั้ง DeepMind
จบ computer science จาก Cambridge รุ่นเดียวกับ David Silver
และเป็นคนสอน David Silver เล่นโกะด้วย
เป็นอัจฉริยะ ด้านหมากรุก โดยได้ คะแนนระดับ Chess Master ตอนอายุ 14 ปี อายุน้อยเป็นอันดับ 2 ของโลก ณ เวลานั้น
จบปริญญาเอกที่ University College London
ก่อตั้ง DeepMind ในปี 2010 ปี 2014 Google มาเทคโอเวอร์ ด้วยเงิน 400 ล้านปอนด์
ปัจจุบัน มีตำแหน่งเป็น รองหัวหน้า ด้านวิศวกรรม AI ของ Google
แก้ไขเมื่อ 13 มี.ค. |+2016| 22:22
ผู้โพส: gunhotnews ![]() วันที่:13 มี.ค. |+2016| 22:21
วันที่:13 มี.ค. |+2016| 22:21
![]()
7
เพิ่มเติมจากคุณ AKB-SKE เว็บไชต์พันทิป
 David Silver
หัวหน้าทีมพัฒนา Google DeepMind AlphaGO
จบ computer science จาก Cambridge ด้วยคะแนน เป็นที่ 1 ของรุ่น
แล้วออกไปตั้งบริษัท ทำเกม Elixir Studios ซึ่งได้รางวัลด้าน เทคโนโลยีมามากมาย
ก่อนที่จะกลับมาทำงานด้านวิชาการ เรียนปริญญาเอกที่ University of Alberta
`ในหัวข้อ reinforcement learning in computer Go
กลับมาทำงานที่ University College London และเข้าร่วม deepmind ในปี 2013
David Silver
หัวหน้าทีมพัฒนา Google DeepMind AlphaGO
จบ computer science จาก Cambridge ด้วยคะแนน เป็นที่ 1 ของรุ่น
แล้วออกไปตั้งบริษัท ทำเกม Elixir Studios ซึ่งได้รางวัลด้าน เทคโนโลยีมามากมาย
ก่อนที่จะกลับมาทำงานด้านวิชาการ เรียนปริญญาเอกที่ University of Alberta
`ในหัวข้อ reinforcement learning in computer Go
กลับมาทำงานที่ University College London และเข้าร่วม deepmind ในปี 2013
ผู้โพส: gunhotnews ![]() วันที่:13 มี.ค. |+2016| 22:18
วันที่:13 มี.ค. |+2016| 22:18
![]()

